Sovereign search at scale.
A detailed benchmark.
A regulated organisation’s AI tools die in security review because their data legally cannot leave the perimeter. Enclave is built so it doesn’t have to. This report covers exactly what we tested to prove it, on what data, and the numbers, including the bug we found and the claim we retired.
We benchmarked the one question
a CISO always asks.
Enclave deploys AI retrieval inside the customer’s own cloud account. The search index lives on the customer’s object storage; the customer holds the keys; Enclave principals are architecturally excluded from key policy. There is no Enclave-operated service holding the customer’s data.
That design invites a fair, direct challenge from any CISO, platform engineer, or technical investor evaluating us. So we put it to the test on public datasets, on a synthetic corpus scaled to a million chunks, and on real AWS S3.
If the index lives on the customer’s object storage instead of in memory, doesn’t search get slow and expensive as the corpus grows? Doesn’t sovereignty cost you speed?
We’re publishing the methodology, the results, and the things that didn’t work, because for a company whose entire promise is trust the architecture, only a benchmark a CISO can scrutinise is worth anything.
A clarification on framing
Our moat is sovereignty, not raw retrieval quality. We use a standard embedding model, the same retrieval-quality component every vendor uses. We are not claiming to win an embedding leaderboard. We are claiming something different and, for our buyer, more important: competitive retrieval that runs entirely inside the customer’s perimeter, fast and cheap, at scale.
Five tests. Public data,
synthetic scale, and real S3.
| Test | Data | Scale | What it measured |
|---|---|---|---|
| Scale curve | Synthetic 768-d vectors | 100K → 1M chunks | Latency, bytes-per-query, memory as corpus grows |
| Real-data quality | FiQA-2018 (BEIR) | 57,638 chunks | Recall@20, NDCG, vs. an in-memory baseline |
| Permission-aware retrieval | FiQA + SciFact + NFCorpus | 4 configurations | Recall under heavy permission restriction |
| Real-S3 latency | FiQA-2018 on AWS S3 | 57,638 chunks | End-to-end latency on actual object storage |
| Edge-cache validation | FiQA-2018 on AWS S3 | 57,638 chunks | Cache impact on warm and cold latency |
Methodology · held constant
HNSW search throughout. Embeddings generated with a fully local model (nomic-embed-text-v2-moe via Ollama), no external API anywhere in the pipeline, consistent with the sovereign architecture. Public datasets from the BEIR benchmark suite. The harness lives in our repository under benchmarks/, and every number here is generated directly from its JSON output. Test runs from a developer laptop unless stated otherwise; cross-region (laptop → us-east-1) where storage is real S3.
Bytes read per query stays flat
as the corpus grows 10×.
~13 KB
read per query
1.04×
I/O for 10× the data

At 100,000 chunks, a query reads 13,089 bytes from storage. At 1,000,000 chunks, ten times the corpus, a query reads 13,609 bytes. The number of distinct storage reads per query is near-constant: about 204 reads at 100K, about 213 at 1M, each one small (~64 bytes).
For a sovereign deployment, this is the entire game. The index can sit on the customer’s object storage at any scale, and each query still costs roughly 13 KB of byte-range reads. It is the property that makes sovereign-on-storage retrieval economically viable at sizes where holding everything in RAM is not.
The layer-0 edge cache:
~53 seconds to under 1 ms.
This is the result we are proudest of, because of how we arrived at it. When we first ran the benchmark on real AWS S3 (FiQA, 57,638 chunks, us-east-1), queries took approximately 53 seconds. Warm and cold latency were essentially identical, a clear signal that something was structurally wrong. Investigation surfaced a missing cache layer for a specific class of storage reads. We added the cache.
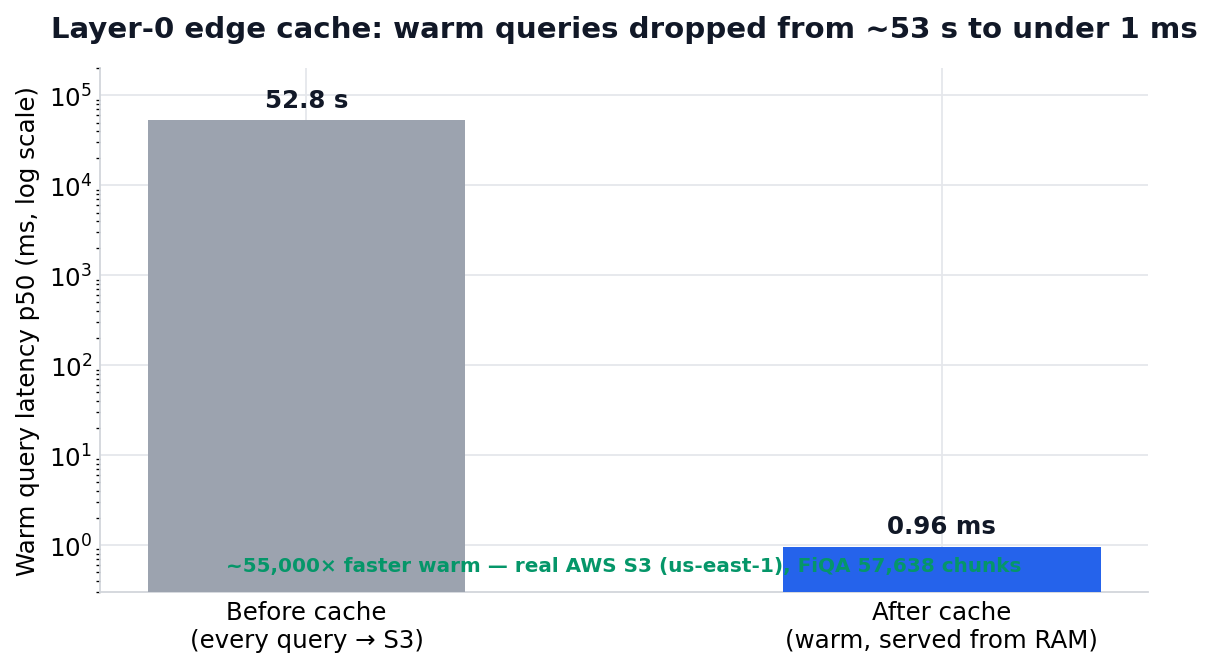
| Before | After (warm) | |
|---|---|---|
| Warm query p50 | 52,835 ms | 0.96 ms |
| Cache hit rate | 0% | 100% |
| Bytes-per-query | ~13 KB | ~13 KB |
Roughly a 55,000× improvement. Bytes-per-query stayed identical, because the cache changes where repeated reads are served from, not what the engine reads off storage.
The reason we publish this first is not the latency number; it is the path to it. The benchmark caught a real product gap. We fixed it transparently, re-measured, and report both the before and the after. For a sovereignty company, that loop is the most important thing we can show.
The full latency profile,
and what we’re honest about.
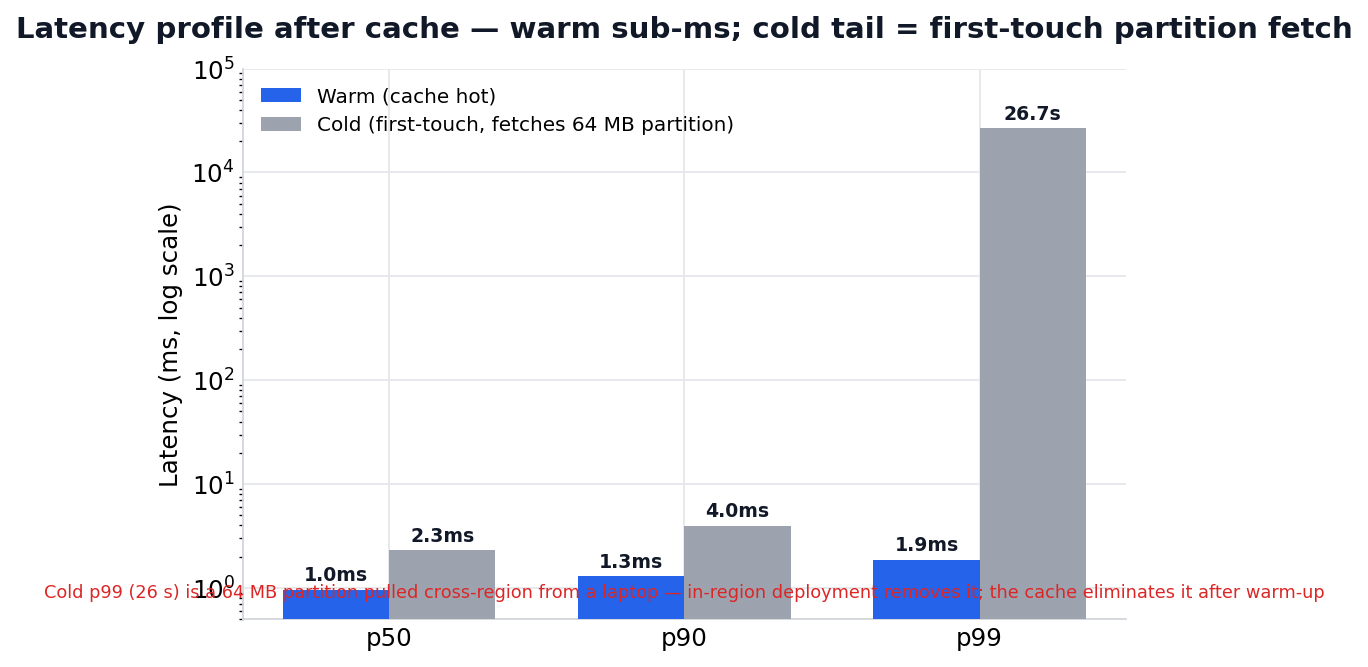
| Pctile | Warm | Cold |
|---|---|---|
| p50 | 0.96 ms | 2.31 ms |
| p90 | 1.30 ms | 3.96 ms |
| p99 | 1.87 ms | 26,653 ms |
Warm latency is excellent across all percentiles. Cold p50 and p90 are low single-digit milliseconds; the cache absorbs most cold queries because they hit edge partitions a prior query already pulled.
Cold p99 · the honest part
Cold p99 is 26 seconds, and we want to be direct about what that is. It captures first-touch reads: the first time a query needs a graph region that isn’t cached yet, the engine fetches a 64 MB edge partition from S3. From a laptop reading cross-region to us-east-1 over a residential network, that single fetch takes seconds. This number is pessimistic by test design. A production deployment runs Enclave inside the customer’s own region, co-located with their S3, where that fetch is intra-region. We report the laptop number because it is what we measured; the in-region number will be materially lower, and we will publish it when we run it.
Retrieval quality is competitive
on real benchmark data.
Synthetic random vectors measure cost well, but they are meaningless for quality. So quality was measured separately on FiQA-2018 (financial-domain question answering from the BEIR suite): 57,638 corpus chunks, embedded with the fully local model described above.

| Metric | Enclave | In-memory |
|---|---|---|
| Recall@20 | 0.497 | 0.518 |
| NDCG@10 | 0.330 | (comparable) |
| Hybrid latency | 59 ms | 169 ms |
Reading 1 · Quality
Enclave’s recall@20 is within roughly 2 points of the in-memory baseline. The sovereign architecture does not cost a meaningful amount of retrieval quality. We are slightly behind on recall, and we report that plainly rather than rounding it away.
Reading 2 · Latency
End-to-end latency is favourable here (59 ms vs 169 ms). We treat this directionally rather than as a universal “3× faster” claim. The headline we stand behind is parity-on-quality plus the sovereignty guarantee the baseline cannot offer.
A claim we tested
and then retired.
This is the part most companies wouldn’t publish. We’re publishing it because it is exactly what makes the rest of this report trustworthy. We hypothesised that filtering permissions during the search would preserve recall under heavy restriction better than a post-filter approach that retrieves a fixed pool and filters afterward.

We tested four controlled configurations on FiQA: random versus semantically clustered permission sets, brute-force versus HNSW baselines, post-filter pools of 50 / 100 / 400.
Across every configuration the recall difference was +0.001 or smaller. No measurable advantage.
So we retired the claim. Permission filtering in Enclave is correct, a restricted user only ever sees permitted results, it simply achieves the same recall as the simpler approach, not better. Finding this on public data, privately, was the benchmark doing its job: it caught an unsupported claim before it ever reached a customer’s security review.
What these numbers prove
about engine credibility.
- Sovereign-scale retrieval is real. Approximately 13 KB read per query, near-flat across a 10× corpus increase, on object storage.
- Warm retrieval is sub-millisecond on real AWS S3 once the partition cache is hot, verified end-to-end against an actual S3 bucket.
- The system survived a real bug, found and fixed transparently. The cache gap was surfaced by the benchmark, fixed, and re-measured. The 55,000× improvement is real, and so is the discovery process.
- Retrieval quality is competitive with an in-memory baseline (recall@20 0.497 vs 0.518 on FiQA), using a fully local embedding pipeline.
- We retire claims that don’t hold up. Honesty is part of the architecture, not a footnote on it.
A hosted vector database can absolutely be fast, by holding the customer’s index in its memory, in its cloud, under its keys. The thing it structurally cannot do is keep the index inside the customer’s perimeter. These numbers are the evidence that doing it the sovereign way doesn’t force a meaningful tradeoff on speed.
What we’re honest about,
and what comes next.
- Cold p99 was measured cross-region from a laptop, a deliberately pessimistic network path. The co-located, in-region number will be materially lower, and we will publish it when we run it.
- Scale was tested to 1,000,000 chunks, not 10 million. The architecture is designed to extend further; we claim what we measured.
- There are engine optimisations on the roadmap that should further reduce cold-cache latency. Those land in the next product cycle.
- Quality is proven on clean public data (FiQA). Real enterprise documents, messier and domain-specific, are the next and more important test.
Part 2 · the benchmark that matters most
The full pipeline, ingestion, embedding, retrieval, answer, running on a real ~1,200-document enterprise corpus inside a real deployment. This report is Part 1: the retrieval engine on public data. Part 2 will be the full system on real enterprise data. We’ll publish it when it lands.
For a regulated buyer
Enclave delivers competitive retrieval quality, sub-millisecond warm latency, and ~13 KB of storage I/O per query, running entirely inside your own perimeter, against your own object storage, with your own keys. The benchmark above is the evidence that doing it the sovereign way does not cost you speed.
For an engineer reading this
The methodology, the harness, and the raw JSON for every number above are in our repository. We retire claims that don’t hold. We publish the loop, not just the headline.
If you are evaluating sovereign AI for a regulated environment and want to scrutinise this benchmark, or run the suite on your own corpus, we’d welcome the conversation.